这篇工作在原始的DDPM(去噪扩散概率模型)的基础上进行改进,针对扩散模型生成样本/采样速度慢的问题提出解决方案,同时保留了扩散模型高采样质量、模式覆盖多/多样性的优势。
动机
作者提出当下的生成学习框架无法很好地同时满足以下三个要求:
- 高采样质量
- 模式覆盖与多样性
- 快速的、低计算开销的采样
作者首先讨论了为什么去噪过程需要小的步长,这也是导致去噪过程总步数多、采样速度慢的主要原因;接着作者提出了解决方案,即对于去噪过程的模型,用多模态分布代替原始Diffusion Model中的高斯分布。
去噪分布是高斯分布这一前提假设导致小的步长不可避免,从而导致总步数多,采样慢。
因此,自然地能够想到要增大步长以减小去噪过程的总步数,就需要更换假设,用别的分布来建模真实的去噪分布。作者从数据分布入手:
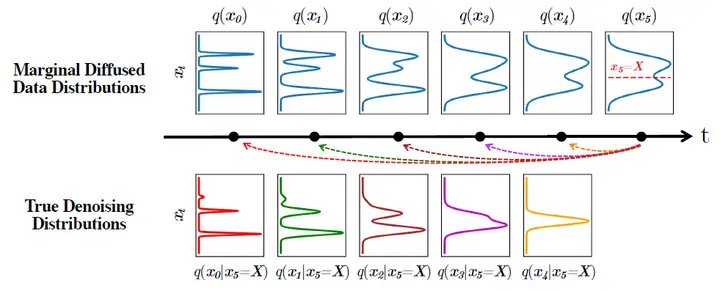
其中第一行是正向扩散过程中,数据分布 q(x_0) 的变化过程;第二行是给定固定的 x5 ,改变步长得到的真实去噪分布。
从图中我们可以看到,在正向加噪过程中随着逐步地添加高斯噪声,数据分布越来越接近单模的高斯分布;而在去噪过程中,如果我们如同原始设定一样用小的步长,一次只走一步,那么真实去噪分布是接近高斯分布的,但当步长增加时分布变得更加复杂以及多模态。
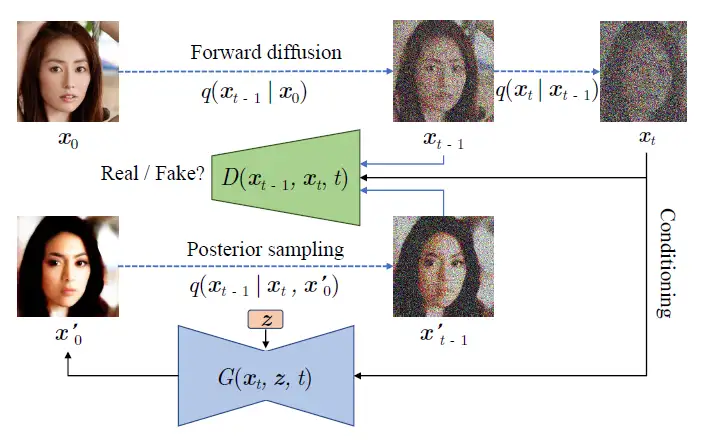
针对这种现象,作者提出用更有表达能力的多模态分布来建模这个去噪分布。由于条件GAN已被证明可以在图片领域建模复杂的条件分布,作者选用条件GAN来估计真实去噪分布.
设定
前向扩散过程与原来的DDPM模型一致
训练目标方面,训练旨在利用最小化对抗性损失,这个对抗性损失能够最小化散度
从而提高条件GAN的生成器 与 真实去噪分布 的匹配程度
具体到对抗训练方面,与时间有关的判别器。让来自真实分布的样本输出的置信度尽可能高,来着虚假样本输出置信度尽可能低。
重参数
相比于原来的DDPM,现在的去噪模型更加复杂,且是一个隐式的模型(原来的建模只是简单的高斯分布)。但是由于正向扩散过程仍然是加的高斯噪声,因此无论步长多大或者数据分布多复杂,依然有$$服从高斯分布这一性质、
- 原DDPM是以确定的映射方式由x_t预测x_0,而作者的设计中x_0是由带随机隐变量z的生成器得到的。使得去噪分布模型变得多模态且更复杂,而原DDPM的去噪模型是简单的、单模态的高斯分布。
- 对于不同的时间t,x_t相对于原始图像的扰动程度是不同的。作者的生成器只需要预测未经扰动的x_0燃火再利用$$加回扰动